
One measure of “unsortedness” in a sequence is the number of pairs of entries that are out of order with respect to each other. For instance, in the letter sequence DAABEC, this measure is 5, since D is greater than four letters to its right and E is greater than one letter to its right. This measure is called the number of inversions in the sequence. The sequence AACEDGG has only one inversion (E and D) — it is nearly sorted — while the sequence ZWQM has 6 inversions (it is as unsorted as can be — exactly the reverse of sorted).
You are responsible for cataloging a sequence of DNA strings (sequences containing only the four letters A, C, G, and T). However, you want to catalog them, not in alphabetical order, but rather in order of “sortedness,” from “most sorted” to “least sorted.” All the strings are of the same length.
Input
The first line of the input is an integer M, then a blank line followed by M datasets. There is a blank line between datasets.
The first line of each dataset contains two integers: a positive integer n (0 < n <= 50) giving the length of the strings; and a positive integer m (0 < m <= 100) giving the number of strings. These are followed by m lines, each containing a string of length n.
Output
For each dataset, output the list of input strings, arranged from “most sorted” to “least sorted.” If two or more strings are equally sorted, list them in the same order they are in the input file.
Print a blank line between consecutive test cases.
Time limit: 3.000 seconds
Sample Input
1
10 6
AACATGAAGG
TTTTGGCCAA
TTTGGCCAAA
GATCAGATTT
CCCGGGGGGA
ATCGATGCAT
Sample Output
CCCGGGGGGA
AACATGAAGG
GATCAGATTT
ATCGATGCAT
TTTTGGCCAA
TTTGGCCAAA
Solution below . . .
Solution
Since the strings are relatively short, the naive 
We can, however, use the fact that the size of the alphabet — only 4 symbols — is small compared to the maximum length (50) of n to implement an optimization, doing the inversion count in 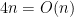
We maintain a 4 by n array that keeps track of how many occurrences of each character there are after the ith character in the string. We do this by scanning the string back to front for each letter in alphabetical order.
For example, consider the string AACATGAAGG. We start by processing the letter A, after which the counts matrix looks as below and count = 0, since no letter to the right of an A creates an inversion.
String: A A C A T G A A G G col: 0 1 2 3 4 5 6 7 8 9 A: 4 3 3 2 2 2 1 0 0 0 C: 0 0 0 0 0 0 0 0 0 0 G: 0 0 0 0 0 0 0 0 0 0 T: 0 0 0 0 0 0 0 0 0 0
After processing the letter C. The matrix shows that the C in column 2 has 3 As to the right, so we add 3 to count and count = 3.
String: A A C A T G A A G G col: 0 1 2 3 4 5 6 7 8 9 A: 4 3 3 2 2 2 1 0 0 0 C: 1 1 0 0 0 0 0 0 0 0 G: 0 0 0 0 0 0 0 0 0 0 T: 0 0 0 0 0 0 0 0 0 0
After processing the letter G. The matrix shows that the G in column 5 has 2 As to the right, so we add 2 to count and count = 5.
String: A A C A T G A A G G col: 0 1 2 3 4 5 6 7 8 9 A: 4 3 3 2 2 2 1 0 0 0 C: 1 1 0 0 0 0 0 0 0 0 G: 3 3 3 3 3 2 2 1 1 0 T: 0 0 0 0 0 0 0 0 0 0
After processing the letter T. The matrix shows that the T in column 4 has 3 Gs and 2 As to the right, added to the previous count of 5 gives a total inversion count of 10.
String: A A C A T G A A G G col: 0 1 2 3 4 5 6 7 8 9 A: 4 3 3 2 2 2 1 0 0 0 C: 1 1 0 0 0 0 0 0 0 0 G: 3 3 3 3 3 2 2 1 1 0 T: 1 1 1 1 0 0 0 0 0 0
import java.util.Arrays;
import java.util.Scanner;
class Dna implements Comparable<Dna> {
String s;
int count;
Dna(String s, int count) {
this.s = s;
this.count = count;
}
@Override
public int compareTo(Dna o) {
return count - o.count;
}
}
class Main {
static int count(String s) {
final char[] LETTERS = new char[] {'A', 'C', 'G', 'T'};
int counts[][] = new int[LETTERS.length][s.length()];
int count = 0;
for (int i = 0; i < LETTERS.length; i++) {
char letter = LETTERS[i];
int letterCount = 0;
for (int j = s.length() - 1; j >= 0; j--) {
counts[i][j] = letterCount;
if (s.charAt(j) == letter) {
letterCount++;
for (int k = 0; k < i; k++) {
count += counts[k][j];
}
}
}
}
return count;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int M = sc.nextInt();
while (M-- > 0) {
int n = sc.nextInt();
int m = sc.nextInt();
Dna[] dna = new Dna[m];
for (int i = 0; i < m; i++) {
String line = sc.next();
// The computation ensures a stable sort, as required
dna[i] = new Dna(line, count(line) * 10000 + i);
}
Arrays.sort(dna);
for (Dna d : dna) {
System.out.println(d.s);
}
if (M > 0)
System.out.println();
}
sc.close();
}
}
What is the sort name in this code?