
Description
For each prefix of a given string S with N characters (each character has an ASCII code between 97 and 126, inclusive), we want to know whether the prefix is a periodic string. That is, for each i (2 <= i <= N) we want to know the largest K > 1 (if there is one) such that the prefix of S with length i can be written as AK, that is A concatenated K times, for some string A. Of course, we also want to know the period K.
Input
The input consists of several test cases. Each test case consists of two lines. The first one contains N (2 <= N <= 1,000,000) – the size of the string S. The second line contains the string S. The input file ends with a line, having the number zero on it.
Output
For each test case, output “Test case #” and the consecutive test case number on a single line; then, for each prefix with length i that has a period K > 1, output the prefix size i and the period K separated by a single space; the prefix sizes must be in increasing order. Print a blank line after each test case.
Sample Input
3 aaa 12 aabaabaabaab 0
Sample Output
Test case #1 2 2 3 3 Test case #2 2 2 6 2 9 3 12 4
Solution below . . .
Solution
The basic string matching problem in computer science is this: given a text 

If 

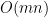
Since this problem allows string lengths up to 1,000,000 characters, we’re going to need a faster, i.e., linear rather than quadratic, algorithm.
We’re trying to find if a given string 

- Find the length of the longest proper prefix of
. (This can be computed in
time using the pre-processing step of the Knuth-Morris-Pratt (KMP) string matching algorithm.)
- If
, then return true; else return false.
First we define a proper prefix of a string of length 
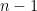
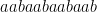
a aa aab aaba aabaa aabaab aabaaba aabaabaa aabaabaab aabaabaaba aabaabaabaa
A key element of the KMP algorithm is a pre-processing step that allows the algorithm to skip some comparisons in the subsequent search process. The pre-processing step creates an LSP (longest suffix-prefix) array, which is exactly what we need for this problem.
For example, here’s the LSP array for
Pattern: a a b a a b a a b a a b LSP : 0 1 0 1 2 3 4 5 6 7 8 9 i : 1 2 3 4 5 6 7 8 9 10 11 12
What this means is that for each 
![LSP[i]](http://s0.wp.com/latex.php?latex=LSP%5Bi%5D&bg=ffffff&fg=000&s=0&c=20201002)
You should be able to convince yourself from the above table that the proposed algorithm works, i.e., that for ![LSP[i] \neq 0](http://s0.wp.com/latex.php?latex=LSP%5Bi%5D+%5Cneq+0&bg=ffffff&fg=000&s=0&c=20201002)
![i\ mod\ (i - LSP[i]) = 0](http://s0.wp.com/latex.php?latex=i%5C+mod%5C+%28i+-+LSP%5Bi%5D%29+%3D+0&bg=ffffff&fg=000&s=0&c=20201002)
![i\ /\ (i - LSP[i])](http://s0.wp.com/latex.php?latex=i%5C+%2F%5C+%28i+-+LSP%5Bi%5D%29&bg=ffffff&fg=000&s=0&c=20201002)
import java.util.Scanner;
public class Main {
static void computeLPSArray(String str, int M) {
int len = 0;
int i;
int[] lps = new int[M];
lps[0] = 0; // lps[0] is always 0
i = 1;
// calculate the rest of the lps array
while (i < M) {
if (str.charAt(i) == str.charAt(len)) {
len++;
lps[i] = len;
i++;
if (len > 0 && i % (i - len) == 0) {
System.out.println(i + " " + (i / (i - len)));
}
} else {
if (len != 0) {
len = lps[len - 1];
} else {
lps[i] = 0;
i++;
}
}
}
}
public static void main(String[] args) {
int count = 1;
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
int N = sc.nextInt();
if (N == 0)
break;
String S = sc.next();
System.out.println("Test case #" + count);
computeLPSArray(S, N);
System.out.println();
count++;
}
sc.close();
}
}